Performance Testing : There are lot of Definitions available but the one mentioned in IEEE Glossary is as follows:
“Testing conducted to evaluate the compliance of a system or component with specified performance requirements. Often this is performed using an automated test tool to simulate large number of users. Also known as "Load Testing".
Or
“The testing performed to determine the degree to which a system or component accomplishes its designated functions within given constraints regarding processing time and throughput rate.”
The purpose of the test is to measure characteristics, such as response times, throughput or the mean time between failures (for reliability testing)
Performance testing tool:A tool to support performance testing and that usually has two main facilities: load generation and test transaction measurement. Load generation can simulate either multiple users or high volumes of input data. During execution, response time measurements are taken from selected transactions and these are logged. Performance testing tools normally provide reports based on test logs and graphs of load against response times.
Features or characteristics of performance-testing tools include support for:
• generating a load on the system to be tested;
• measuring the timing of specific transactions as the load on the system varies;
• measuring average response times;
• producing graphs or charts of responses over time.
Load test:
A test type concerned with measuring the behavior of a component or system with increasing load, e.g. number of parallel users and/or numbers of transactions to determine what load can be handled by the component or system
While doing Performance testing we measure some of the following:
- Characterisitics (SLA) Measurement (units)
- Response Time Seconds
- Hits per Second #Hits
- Throughput Bytes Per Second
- Transactions per Second (TPS) #Transactions of a Specific Business Process
- Total TPS (TTPS) Total no.of Transactions
- Connections per Second (CPS) #Connections/Sec
- Pages Downloaded per Second (PDPS) #Pages/Sec
The objective of a performance test is to ensure that the application is working perfectly under load. However, the definition of “perfectly” under load may vary with different systems.
By defining an initial acceptable response time, we can benchmark the application if it is performing as anticipated.
The importance of Transaction Response Time is that it gives the project team/ application team an idea of how the application is performing in the measurement of time. With this information, they can relate to the users/customers on the expected time when processing request or understanding how their application performed.
What does Transaction Response Time encompass?
The Transaction Response Time encompasses the time taken for the request made to the web server, there after being process by the Web Server and sent to the Application Server. Which in most instances will make a request to the Database Server. All this will then be repeated again backward from the Database Server, Application Server, Web Server and back to the user. Take note that the time taken for the request or data in the network transmission is also factored in.
To simplify, the Transaction Response Time comprises of the following:
1. Processing time on Web Server
2. Processing time on Application Server
3. Processing time on Database Server.
4. Network latency between the servers, and the client.
The following diagram illustrates Transaction Response Time.
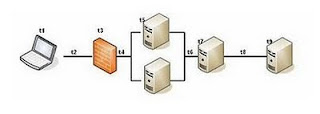
Transaction Response Time = (t1 + t2 + t3 + t4 + t5 + t6 + t7 + t8 + t9) X 2
Note:
Factoring the time taken for the data to return to the client.
How do we measure?
Measuring of the Transaction Response Time begins when the defined transaction makes a request to the application. From here, till the transaction completes before proceeding with the next subsequent request (in terms of transaction), the time is been measured and will stop when the transaction completes.
Differences with Hits Per Seconds
Hits per Seconds measures the number of “hits” made to a web server. These “hits” could be a request made to the web server for data or graphics. However, this counter does not represent well to users on how well their applications is performing as it measures the number of times the web server is being accessed.
How can we use Transaction Response Time to analyze performance issue?
Transaction Response Time allows us to identify abnormalities when performance issues surface. This will be represented as slow response of the transaction, which differs significantly (or slightly) from the average of the Transaction Response Time.
With this, we can further drill down by correlation using other measurements such as the number of virtual users that is accessing the application at the point of time and the system-related metrics (e.g. CPU Utilization) to identify the root cause.
Bringing all the data that have been collected during the load test, we can correlate the measurements to find trends and bottlenecks between the response time, the amount of load that was generated and the payload of all the components of the application.
How is it beneficial to the Project Team?
Using Transaction Response Time, Project Team can better relate to their users using transactions as a form of language protocol that their users can comprehend. Users will be able to know that transactions (or business processes) are performing at an acceptable level in terms of time.
Users may be unable to understand the meaning of CPU utilization or Memory usage and thus using a common language of time is ideal to convey performance-related issues.
Relation between Load, Response Time and Performance:
1. Load is Directly Proportional to Response Time
2. Performance is inversely proportional to Response Time.
So, As and When the Load increases the Response Time Increases. As Response Time Increases, the Performance Decreases.
Hits Per Second
A Hit is a request of any kind made from the virtual client to the application being tested (Client to Server). It is measured by number of Hits. The higher the Hits Per Second, the more requests the application is handling per second.
A virtual client can request an HTML page, image, file, etc. Testing the application for Hits Per Second will tell you if there is a possible scalability issue with the application. For example, if the stress on an application increases but the Hits Per Second does not, there may be a scalability problem in the application.
One issue with this metric is that Hits Per Second relates to all requests equally.
Thus a request for a small image and complex HTML generated on the fly will both be considered as hits. It is possible that out of a hundred hits on the application, the application server actually answered only one and all the rest were either cached on the web server or other caching mechanism.
So, it is very important when looking at this metric to consider what and how the
application is intended to work. Will your users be looking for the same piece of
information over and over again (a static benefit form) or will the same number of users be engaging the application in a variety of tasks – such as pulling up images, purchasing items, bringing in data from another site? To create the proper test, it is important to understand this metric in the context of the application. If you’re testing an application function that requires the site to ‘work,’ as opposed to present static data, use the pages per second measurement.
Pages Per Second
Pages Per Second measures the number of pages requested from the application per second. The higher the Page Per Second the more work the application is doing per second. Measuring an explicit request in the script or a frame in a frameset provides a metric on how the application responds to actual work requests. Thus if a script contains a Navigate command to a URL, this request is considered a page. If the HTML that returns includes frames they will also be considered pages, but any other elements retrieved such as images or JS Files, will be considered hits, not pages. This measurement is key to the end-user’s experience of application performance.
Correlation: If the stress increases, but the Page Per Second count doesn’t, there may be a scalability issue. For example, if you begin with 75 virtual users requesting 25 different pages concurrently and then scale the users to 150, the Page Per Second count should increase. If it doesn’t, some of the virtual users aren’t getting their pages. This could be caused by a number of issues and one likely suspect is throughput.
Throughput
“The amount of data transferred across the network is called throughput. It considers the amount of data transferred from the server to client only and is measured in Bytes/sec.”
This is an important baseline metric and is often used to check that the application and its server connection is working. Throughput measures the average number of bytes per second transmitted from the application being tested to the virtual clients running the test agenda during a specific reporting interval. This metric is the response data size (sum) divided by the number of seconds in the reporting interval.
Generally, the more stress on an application, the more Throughput. If the stress increases, but the Throughput does not, there may be a scalability issue or an application issue.
Another note about Throughput as a measurement – it generally doesn’t provide any information about the content of the data being retrieved. Thus it can be misleading especially in regression testing. When building regression tests, leave time in the testing plan for comparing returned data quality.
Round Trips
Another useful scalability and performance metric is the testing of Round Trips. Round Trips tells you the total number of times the test agenda was executed versus the total number of times the virtual clients attempted to execute the Agenda. The more times the agenda is executed, the more work is done by the test and the application.
The test scenario the agenda represents influences the round Trips measurement.
This metric can provide all kinds of useful information from the benchmarking of an application to the end-user availability of a more complex application. It is not
recommended for regression testing because each test agenda may have a different scenario and/or length of scenario.
Hit Time:
Hit time is the average time in seconds it took to successfully retrieve an element of any kind (image, HTML, etc). The time of a hit is the sum of the Connect Time, Send Time, Response Time and Process Time. It represents the responsiveness or performance of the application to the end user. The more stressed the application, the longer it should take to retrieve an average element. But, like Hits Per Second, caching technologies can influence this metric. Getting the most from this metric requires knowledge of how the application will respond to the end user.
This is also an excellent metric for application monitoring after deployment.
Time to First Byte
This measurement is important because end users often consider a site malfunctioning if it does not respond fast enough. Time to First Byte measures the number of seconds it takes a request to return its first byte of data to the test software’s Load Generator.
For example, Time to First Byte represents the time it took after the user pushes the “enter” button in the browser until the user starts receiving results. Generally, more concurrent user connections will slow the response time of a request. But there are also other possible causes for a slowed response.
For example, there could be issues with the hardware, system software or memory issues as well as problems with database structures or slow-responding components within the application.
Page Time
Page Time calculates the average time in seconds it takes to successfully retrieve a page with all of its content. This statistic is similar to Hit Time but relates only to pages. In most cases this is a better statistic to work with because it deals with the true dynamics of the application. Since not all hits can be cached, this data is more helpful in terms of tracking a user’s experience (positive or frustrated). It’s important to note that in many test software application tools you can turn caching on or off depending on your application needs.
Generally, the more stress on the site the slower its response. But since stress is a combination of the number of concurrent users and their activity, greater stress may or may not impact the user experience. It all depends upon the application’s functions and users. A site with 150 concurrent users looking up benefit information will differ from a news site during a national emergency. As always, metrics must be examined within context.
Failed Rounds/Failed Rounds Per Second
During a load test it’s important to know that the application requests perform as
expected. The Failed Rounds and Failed Rounds Per Second tests the number of
rounds that fail.
This metric is an “indicator metric” that provides QA and test with clues to the
application performance and failure status. If you start to see Failed Rounds or Failed Rounds Per Second, then you would typically look into the logs to see what types of failures correspond to this metric report. Also, with some software test packages, you can set what the definition of a failed round in an application.
Sometimes, basic image or page missing errors (HTTP 404 error codes) could be set to fail a round, which would stop the execution of the test agenda at that point and start at the top of the agenda again, thus not completing that particular round.
Failed Hits/Failed Hits Per Second
This test offers insight into the application’s integrity during the load test. An example of a request that might fail during execution is a broken link or a missing image from the server. The number of errors should grow with the load size. If there are no errors with a low load, the number of errors with a high load should remain zero. If the percentage of errors only increases during high loads, the application may have a scalability issue.
Failed Connections
This test is simply the number of connections that were refused by the application during the test. This test leads to other tests. A failed connection could mean the server was too busy to handle all the requests, so it started refusing them. It could be a memory issue. It could also mean that the user sent bogus or malformed data to which the server couldn’t respond so it refused the connection.










