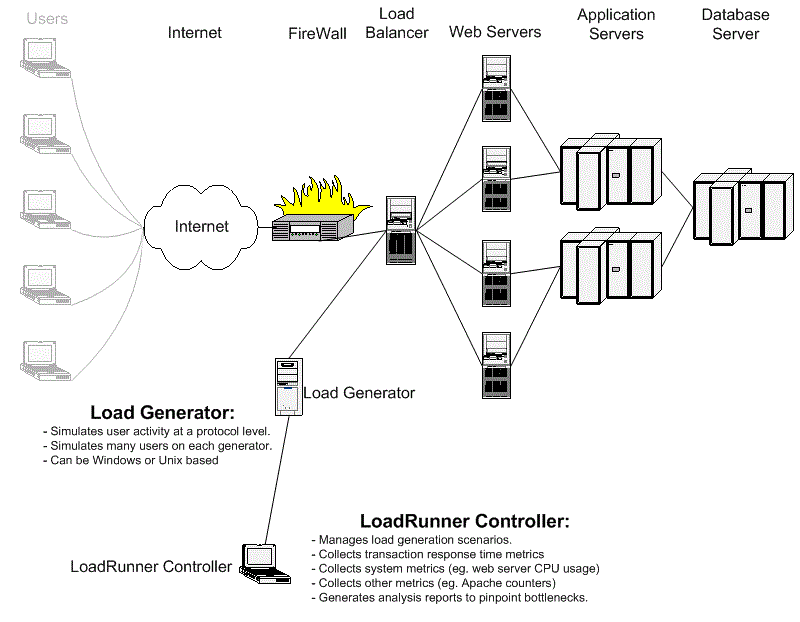
Stress Tests determine the load under which a system fails, and how it fails. This is in contrast to Load Testing, which attempts to simulate anticipated load. It is important to know in advance if a ‘stress’ situation will result in a catastrophic system failure, or if everything just “goes really slow”.
There are various varieties of Stress Tests, including spike, stepped and gradual ramp-up tests. Catastrophic failures require restarting various infrastructure and contribute to downtime, a stress-full environment for support staff and managers, as well as possible financial losses. If a major performance bottleneck is reached, then the system performance will usually degrade to a point that is unsatisfactory, but performance should return to normal when the excessive load is removed.

Before conducting a Stress Test, it is usually advisable to conduct targeted infrastructure tests on each of the key components in the system. A variation on targeted infrastructure tests would be to execute each one as a mini stress test.
The diagram below shows an unexpectedly high amount of demand on a typical web system. Stress situations are not expected under normal circumstances.
The following table lists possible situations for a variety of applications where stress situations may occur.
Focus of stress test.
In a stress event, it is most likely that many more connections will be requested per minute than under normal levels of expected peak activity. In many stress situations, the actions of each connected user will not be typical of actions observed under normal operating conditions. This is partly due to the slow response and partly due to the root cause of the stress event.
Lets take an example of a large holiday resort web site. Normal activity will be characterized by browsing, room searches and bookings. If a national online news service posted a sensational article about the resort and included a URL in the article, then the site may be subjected to a huge number of hits, but most of the visits would probably be a quick browse. It is unlikely that many of the additional visitors would search for rooms and it would be even less likely that they would make bookings. However, if instead of a news article, a national newspaper advertisement erroneously understated the price of accommodation, then there may well be an influx of visitors who clamour to book a room, only to find that the price did not match their expectations.
In both of the above situations, the normal traffic would be increased with traffic of a different usage profile. So a stress test design would incorporate a Load Test as well as additional virtual users running a special series of 'stress' navigations and transactions.
For the sake of simplicity, one can just increase the number of users using the business processes and functions coded in the Load Test. However, one must then keep in mind that a system failure with that type of activity may be different to the type of failure that may occur if a special series of 'stress' navigations were utilized for stress testing.
Stress test execution.
Typically, a stress test starts with a Load Test, and then additional activity is gradually increased until something breaks. An alternative type of stress test is a Load Test with sudden bursts of additional activity. The sudden bursts of activity generate substantial activity as sessions and connections are established, where as a gradual ramp-up in activity pushes various values past fixed system limitations.

Ideally, stress tests should incorporate two runs, one with burst type activity and the other with gradual ramp-up as per the diagram above, to ensure that the system under test will not fail catastrophically under excessive load. System reliability under severe load should not be negotiable and stress testing will identify reliability issues that arise under severe levels of load.
An alternative, or supplemental stress test is commonly referred to as a spike test, where a single short burst of concurrent activity is applied to a system. Such tests are typical of simulating extreme activity where a 'count-down' situation exists. For example, a system that will not take orders for a new product until a particular date and time. If demand is very strong, then many users will be poised to use the system the moment the count down ends, creating a spike of concurrent requests and load.

Before conducting a Stress Test, it is usually advisable to conduct targeted infrastructure tests on each of the key components in the system. A variation on targeted infrastructure tests would be to execute each one as a mini stress test.
The diagram below shows an unexpectedly high amount of demand on a typical web system. Stress situations are not expected under normal circumstances.
The following table lists possible situations for a variety of applications where stress situations may occur.
|
Focus of stress test.
In a stress event, it is most likely that many more connections will be requested per minute than under normal levels of expected peak activity. In many stress situations, the actions of each connected user will not be typical of actions observed under normal operating conditions. This is partly due to the slow response and partly due to the root cause of the stress event.
Lets take an example of a large holiday resort web site. Normal activity will be characterized by browsing, room searches and bookings. If a national online news service posted a sensational article about the resort and included a URL in the article, then the site may be subjected to a huge number of hits, but most of the visits would probably be a quick browse. It is unlikely that many of the additional visitors would search for rooms and it would be even less likely that they would make bookings. However, if instead of a news article, a national newspaper advertisement erroneously understated the price of accommodation, then there may well be an influx of visitors who clamour to book a room, only to find that the price did not match their expectations.
In both of the above situations, the normal traffic would be increased with traffic of a different usage profile. So a stress test design would incorporate a Load Test as well as additional virtual users running a special series of 'stress' navigations and transactions.
For the sake of simplicity, one can just increase the number of users using the business processes and functions coded in the Load Test. However, one must then keep in mind that a system failure with that type of activity may be different to the type of failure that may occur if a special series of 'stress' navigations were utilized for stress testing.
Stress test execution.
Typically, a stress test starts with a Load Test, and then additional activity is gradually increased until something breaks. An alternative type of stress test is a Load Test with sudden bursts of additional activity. The sudden bursts of activity generate substantial activity as sessions and connections are established, where as a gradual ramp-up in activity pushes various values past fixed system limitations.

Ideally, stress tests should incorporate two runs, one with burst type activity and the other with gradual ramp-up as per the diagram above, to ensure that the system under test will not fail catastrophically under excessive load. System reliability under severe load should not be negotiable and stress testing will identify reliability issues that arise under severe levels of load.
An alternative, or supplemental stress test is commonly referred to as a spike test, where a single short burst of concurrent activity is applied to a system. Such tests are typical of simulating extreme activity where a 'count-down' situation exists. For example, a system that will not take orders for a new product until a particular date and time. If demand is very strong, then many users will be poised to use the system the moment the count down ends, creating a spike of concurrent requests and load.