The NL-Runtime-04 error in Neoload typically occurs when a virtual user requests a unique value in a variable, but there are insufficient values available in the dataset at that time. Essentially, it indicates that the workload being simulated requires more unique values than are currently available.
Causes of NL-Runtime-04 Error:
1. Insufficient Dataset Size: The dataset used by the virtual user may not contain enough unique values to satisfy the workload requirements.
2. Incorrect Variable Population: The process responsible for populating the variable with values may be malfunctioning or not providing enough unique values.
3. Script Logic Issues: Errors in the script logic can result in the virtual user requesting more values from the dataset than are available.
4. Test Configuration Problems: The test configuration, such as the number of virtual users or the duration of the test, may be set in a way that puts excessive demand on the dataset.
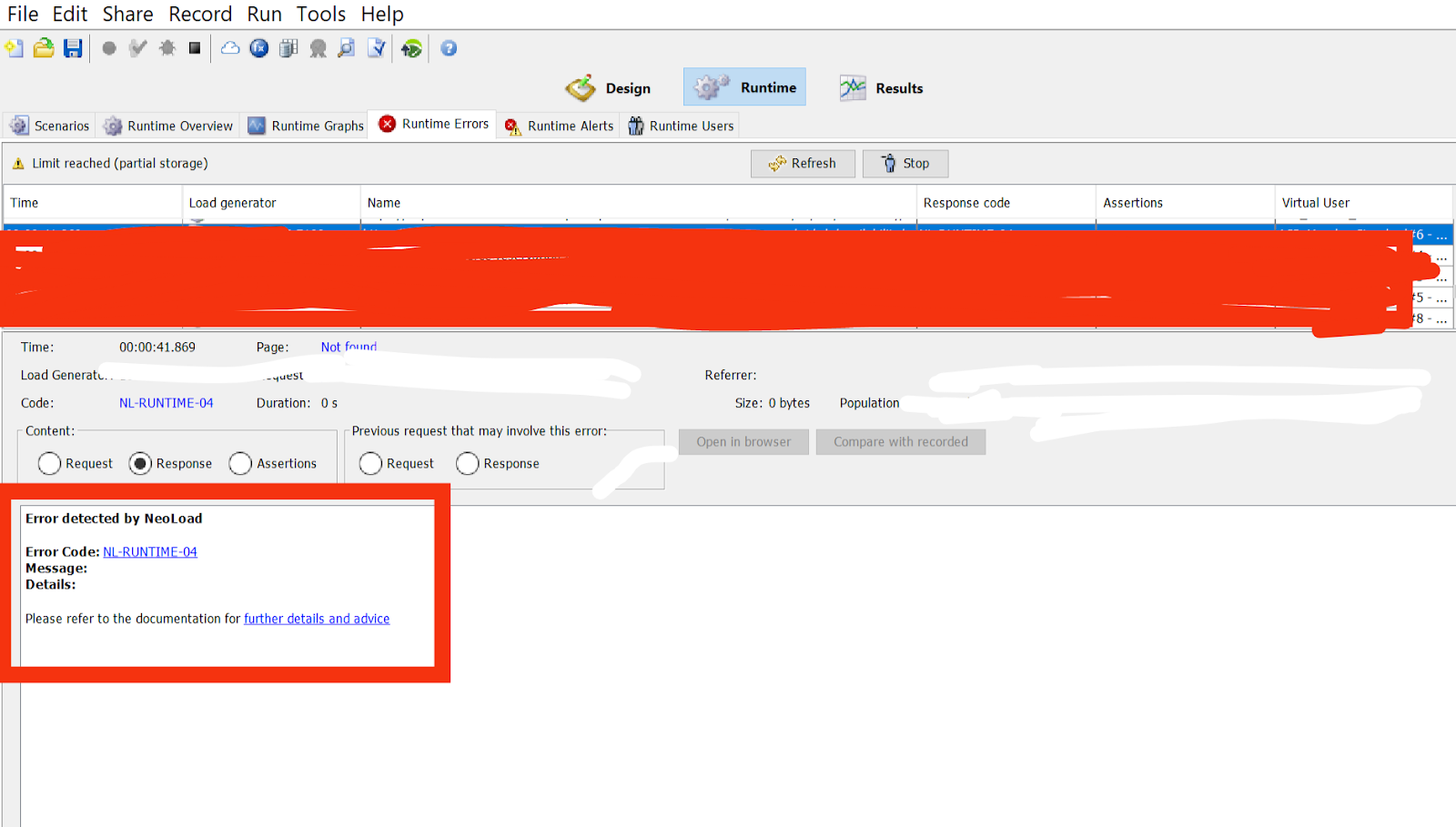
Resolving NL-Runtime-04 Error:
Here are some practical steps to resolve the NL-Runtime-04 error in Neoload:
1. Increase Dataset Size: Expand the dataset to ensure an adequate number of unique values are available for the workload being simulated.
2. Verify Variable Population: Ensure that the process responsible for populating the variable with values is functioning correctly and can provide enough unique values.
3. Review Script Logic: Double-check the script logic to identify and fix any errors related to requesting values from the dataset.
4. Adjust Test Configuration: Consider adjusting the test configuration to reduce the demand for unique values at any given time, such as reducing the number of virtual users or modifying the duration of the test.
5. Monitor Resource Usage: Keep an eye on the resource usage of the Neoload Controller and Load Generators during test execution to ensure they have sufficient resources to handle the workload and dataset requirements.